AI Pacman :video_game: :space_invader: :trophy: (Reinforcement learning)

Project Learn RL with Pacman
We are a group of fellows from the BootCamp DataScientest egear to get familiarize ourselves with reinforcement learning. We have followed mainly the online ressource of UC Berkeley’s introductory artificial intelligence course CS 188 with the support of the book Reinforcement Learning: An introduction of R. S. Sutton and A. G. Barto to achieved our goal: Create an agent to play Pacman!
This website has the purpose to summarize our knowledge on RL and to show our progress to our other Fellows at the BootCamp.
Reinforcement Learning
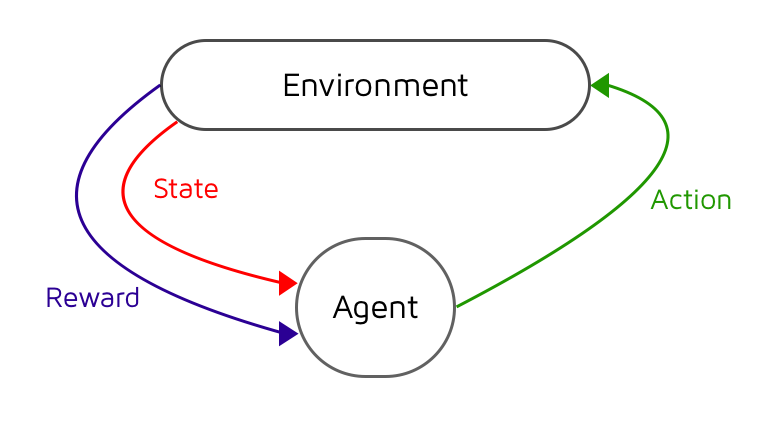
Reinforcement learning (RL) is a machine learning area to find the optimal way to achieve a goal. RL is different from supervised and unsupervised machine learning because there is no “supervisor” to tell the agent the right action to take. In general, the RL agent doesn’t know its environement and have to explore it. Thus, the agent gets to make decision, picks action, see how much rewards it gets and optimizes those decision by maximizing the sum of rewards in long-term.
The interaction between the agent and its environment can be formalized as a Markov Decision Process (MDP). MDP is caracterized principally by three paramaters:
- the state (S) of the syteme
- the possible action A in those state
- the rewards (R) associated with each transition from the starting state to the next state given a specific action A.
In our case, we want our Pacman agent to get the maximum point possible in the different gridworld according to the following rules:
- +10 when it eats a dots
- +200 when it eats a ghost after getting a capsule
- +500 when it eats every dots
- +1 at each action
- -500 when it gets eaten by a ghost
There is many different algorithm avalaible in order to create an agent but here i will be focusing on Q-learning and approximate Q-learning.
Q-Learning
In Q-learning, we affect a value for each action given a particular state with the idea to see how good was to take the action. At the beginning, the agent has a representation of the environment that are the states and the possible actions in those states but doesn’t know the values of thoses parameters. It is during training that the agent will explore the environment and learn the value of each of those actions in each of those states. After it took an action from the state S and arrived to the state S+1, it evaluates the state S by updating the action value Q using this equation :

Let’s says that the learning rate is set to 1 (meaning that the old value is replaced by the updated value) and that the discount factor is set to 1 (no discount). So the updated value is equivalent to sum of the reward obtained and the estimated future rewards. In Q-learning, the estimated future rewards is the highest Q value given next state S+1.
python gridworld.py -a q -k 5 -m

After a number of iteration (number of times the agent try the games), there is an estimated value for each state-action pairs, which will converge eventually to the optimal value after a certain number of iterations.
After evaluating the state, the agent will select which action to take according to a Epsilon-greedy policy that will take the action with the highest Q value with a probability equal to Epsilon to take a random action. The Epsilon greedy policiy allows the agent the possibility to explore the environement even if it finds a good spot of rewards, avoiding the agent to get stuck in the maze and prevent future possible rewards.
python pacman.py -p PacmanQAgent -x 2000 -n 2010 -l smallGrid
python pacman.py -p PacmanQAgent -x 2000 -n 2010 -l mediumGrid
Finally, all the Q values are stored in a table of size N * M, where N is the number of possible states and M is the number of possible actions. To get the optimal policy, which get the maximum rewards, the agent needs to perform a lot of iteration process. This is fine for small gridworld but when the agent evolves in a medium or large gridworld, it needs a huge numbers of iteration taking a long time to train. An efficient way to train the agent in an environment with very large number of state is to use Approximate Q-Learning.
Approximate Q-Learning
One way to reduce the number of iteration is to adress Q value from known state-action to other similar state-action so it reduces drastically the number the agent has to play. This is performed by adding features that sorts out the important informations. In Pacman, for example, the feature #-of ghost one step away, eats-food and closest food are enough to reduce the number of training iteration from over 24000 to 50.
The training consists in computing of Q value from a linear combination of features f(i) given by with a weight-factor w.

Then, the agent updates the the weight value:

python pacman.py -p ApproximateQAgent -a extractor=SimpleExtractor -x 50 -n 60 -l mediumGrid
python pacman.py -p ApproximateQAgent -a extractor=SimpleExtractor -x 50 -n 60 -l mediumClassic
python pacman.py -p ApproximateQAgent -a extractor=SimpleExtractor -x 50 -n 60 -l capsuleClassic